A question comes up in almost every data architecture review. “Our company runs on a data warehouse, but everyone seems to be moving to a lakehouse — should we switch?” The list of options keeps growing: data lake, data warehouse, lakehouse, data mesh, data fabric. Each one solves a different problem, and it is not always clear which fits a specific organization. Chasing the trend rarely helps, because the underlying problem usually stays the same after the tool change.
This article is the second piece in the Data Products and Architecture series. The first article covered how to structure organizational data into elements, domains, and products. This one looks at the technical foundation that makes those designs run. It compares the five main data architecture archetypes side by side, then maps out the 6 capability layers and 4 cross-cutting areas that any organization needs regardless of the archetype, and closes with four practical principles for strengthening those capabilities.
What Is Data Architecture? Core Concepts to Know First
Data architecture is the technical foundation that decides how data is stored, processed, and accessed. A data product cannot run on intent alone — it needs an architecture underneath that determines where raw records land, how they are transformed, and who can read them.
Before comparing the archetypes, a few terms are worth pinning down. A data lake is a central store for raw data of any shape — logs, events, files — kept in cheap object storage. A data warehouse is a structured store optimized for SQL queries and reporting. A lakehouse sits on top of cheap storage but adds the transactional guarantees a warehouse used to monopolize. A data mesh is an organizational pattern, not a storage choice, where business domains own their data as products. A data fabric is a virtual layer that connects data across systems through metadata, without physically moving it.
These five terms describe different answers to the same question — how should an organization shape the path from raw data to decision? The next section walks through each one in the order they tend to appear in a company’s evolution.
The 5 Data Architecture Archetypes

The five archetypes overlap in capability but differ in the problem they were designed to solve. Each one has a best fit, and choosing well depends less on the technology’s maturity than on the workload and team structure the organization already has.
Cloud Native Data Lake: When You Store First, Decide Later
The data lake fits the situation where “data keeps piling up, but we are not sure how we will use it yet.” Logs, event streams, scraped data, third-party feeds — anything with an unpredictable shape goes into cheap object storage and waits. The two strengths are obvious: storage cost is low, and scale is almost free.
The trade-off is just as direct. Raw data is rarely query-ready, so a refinement step has to follow before anything useful comes out. Treating a lake as a finished product tends to produce a swamp instead — raw data piled up without ever being turned into usable form. More recently, the lake has been reinterpreted as a foundation that other archetypes — especially the lakehouse — build on top of, rather than as an end state.
Cloud Native Data Warehouse: When Reports and SQL Are the Center
A cloud-native data warehouse pays off when the questions are already known. If the team has a defined set of KPIs, scheduled reports, and SQL-literate analysts, then a warehouse — BigQuery, Snowflake, Redshift — gives fast, reliable answers. The structure is rigid by design, and that rigidity is what makes the queries fast.
The limit shows up the moment machine learning or unstructured data enters the picture. Warehouses handle tabular, well-defined data well; they handle JSON blobs, image embeddings, or streaming events poorly. For organizations whose data work sits firmly in BI and structured reporting, a warehouse-centered design is still the most rational choice. For anything wider, it becomes a bottleneck.
Lakehouse: When BI and ML Cannot Be Separated
The lakehouse comes from a refusal to choose. In the older split, the analytics team ran a warehouse while the data science team ran a lake, and the same dataset had to be maintained twice — once for each. Technologies like Delta Lake and Apache Iceberg dissolved that boundary by adding ACID transactions and schema evolution to the lake itself.
The core value of the lakehouse is that one copy of data serves both purposes. BI dashboards and ML models read from the same tables. The pattern is especially strong for sensor data, event streams, and any workload that mixes structured queries with model training. The tooling around it is still maturing, but the lakehouse has moved quickly from a niche option to a default reference architecture for new data platforms.
Data Mesh: When Domain Ownership Matters More Than Storage
Data mesh answers a different question than the previous three. The question is not where data sits, but who is responsible for it. Once an organization grows past a certain size, a central IT or data team can no longer understand every domain well enough to model its data correctly. Marketing data, supply chain data, and customer support data each have their own logic, and a single team trying to own all of them becomes the bottleneck.
The mesh idea is to push ownership outward. Each business domain treats its own data as a product, with documented quality, an SLA, and a consumer-facing interface. The data domain and data product concepts from the previous article in this series map directly onto this organizational model. The mesh is less a piece of technology than a contract about who builds and maintains what.
Data Fabric: When You Cannot Move Data Across Clouds
Data fabric is the most pragmatic of the five. Large enterprises usually have data scattered across multiple clouds, on-premise systems, and SaaS tools, and consolidating all of it into one place is rarely feasible for cost, regulatory, or timeline reasons. The fabric proposal: leave the data where it is, and connect it through a metadata layer so that users can query and govern it as if it lived in one place.
The idea is appealing, but the execution is hard. No single commercial product delivers a full data fabric off the shelf, so most organizations assemble one from catalog tools, virtualization engines, and governance platforms. That assembly cost is the realistic barrier between a fabric on a slide and a fabric in production.
Building Data Capabilities: 6 Layers and 4 Cross-Cutting Areas
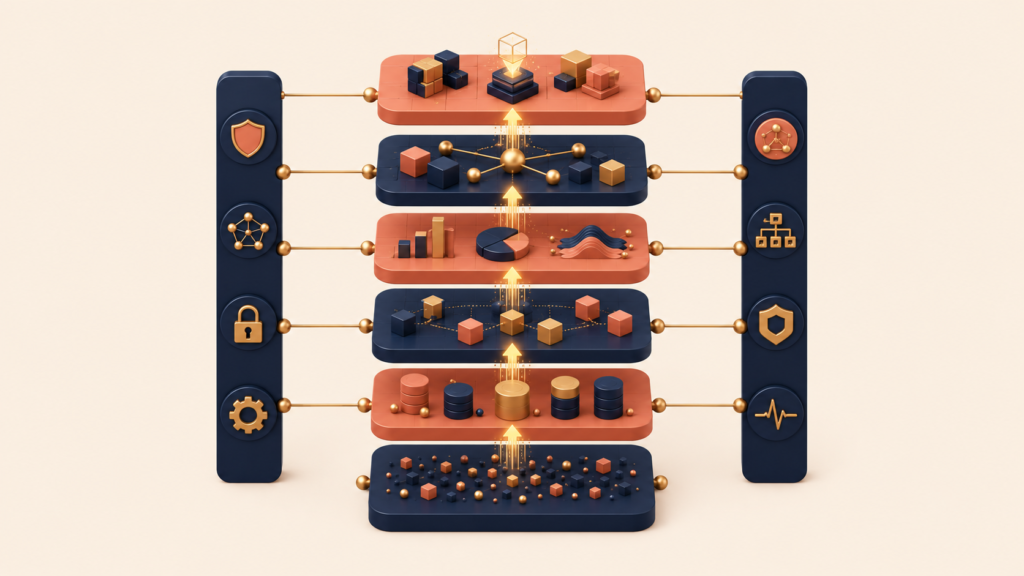
If data products and architecture sit on the design side, data capabilities are the actual function list an organization needs to operate. Capabilities cover every step from the source where data is generated to the consumer who finally uses it. The map below shows how those functions stack into six vertical layers and four cross-cutting areas.
[Data capabilities
— 6 layers flowing bottom to top
+ 4 cross-cutting areas]
┌────────────────────────────┐
│ 6 Data Consumption │
│ BI · Advanced analytics · │
│ Applications │
├────────────────────────────┤
│ 5 Data Services │
│ APIs · Analytics-optimized │ ┌──────────────┐
│ · Feature store │ │ Cross-cutting│
├────────────────────────────┤ │ │
│ 4 Data Repositories │ │ · Pipeline │
│ Object storage · │ │ orchestration│
│ Databases · DWH │ │ · Governance │
├────────────────────────────┤ │ · Data │
│ 3 Data Processing │ │ security │
│ AI/ML · Stream processing │ │ · Infra- │
│ · Batch │ │ structure │
├────────────────────────────┤ │ operations │
│ 2 Data Ingestion │ └──────────────┘
│ Batch ingest · Event │
│ streaming · PII flow │
├────────────────────────────┤
│ 1 Data Sources │
│ Structured · Unstructured │
└────────────────────────────┘
Data flow: bottom to top ▲
Cross-cutting areas:
operate across all 6 layersData flows upward. It is generated at the source, ingested, processed, stored, exposed as a service, and finally consumed by a dashboard, model, or application. Alongside this vertical flow run four cross-cutting areas — pipeline orchestration, governance, security, and infrastructure operations — that touch every layer. No single layer carries the whole load. All six have to mature together for the stack to deliver.
Most organizations sit in an uneven state, where one or two layers are mature and the rest are thin. A common pattern: the ingestion layer is built out with real-time streaming and full pipeline coverage, but the storage or service layer is outdated, so the ingested data never reaches the people who need it. Adding more investment to the already-strong layer does not raise the overall capability — it just widens the gap.
Each layer has its own specialist tooling. Ingestion involves tools like Fivetran, Airbyte, and Kafka. Processing covers Spark, Flink, and ML platforms. Storage spans object stores, relational databases, and warehouses. Services include API gateways and feature stores. Consumption sits in BI tools like Looker and Tableau, plus the applications that read the data directly. The cross-cutting areas — orchestration (Airflow, Dagster), governance (data catalogs, lineage), security (access control, masking), and infrastructure (Terraform, monitoring) — keep the vertical stack coherent.
How to Strengthen Data Capabilities: 4 Practical Principles

Strengthening data capabilities in practice comes down to four principles. Each one starts from a specific failure mode that shows up when organizations try to scale data work without it.
1. Balance the lifecycle. The first move is to audit the full stack against the capability map and find the weakest layer, not the most exciting one. Pouring more budget into the strongest layer feels like progress but produces less and less return. Diagnosing balance requires the map; without it, investment decisions follow whoever shouts loudest.
2. Use flexible data models. Schemas change. Sources change. Business questions change. Data models that treat structure as fixed lock the organization into the questions it could ask three years ago. Flexible models — schema evolution, versioned tables, decoupled storage and compute — keep the platform responsive instead of brittle.
3. Build modular architecture. A monolithic data platform is hard to evolve one piece at a time. Modular architecture lets each layer be swapped, upgraded, or scaled independently. When a new processing engine becomes the standard, the team should be able to adopt it without rebuilding the warehouse. Modularity is what makes the balance principle actionable.
4. Add a semantic layer. A modular stack still confuses end users if every team defines “active user” or “monthly revenue” differently. A semantic layer codifies business definitions — what “active user” or “monthly revenue” means — once and reuses them across BI, ML, and applications. Tools like dbt metrics and LookML give it a place to live. Without it, consistency depends on memory and meetings.
These four principles support each other rather than standing alone. Diagnosing lifecycle balance requires the capability map. Acting on the map requires modular architecture. Modular architecture only delivers consistent answers when a semantic layer sits on top. And all of it runs on flexible data models underneath.
Conclusion
The five data architecture archetypes — lake, warehouse, lakehouse, data mesh, data fabric — each solve a specific problem, and the question is not which one is best in the abstract. The right answer depends on organizational size, maturity, and the dominant workload. Whatever the choice, the capabilities on top of that architecture still have to mature in balance across all six layers.
Data work fails when only one side is built. Strong design without strong implementation produces strategy decks no one uses; strong implementation without strong design produces platforms no one understands. Both the product side and the architecture side have to mature together for data to become a real asset. This closes the Data Products and Architecture series — the hope is that the map and principles here give a useful starting point for reviewing where the organization stands and what to build next.
Data Products and Architecture Series
(1) Data Product Architecture: The 3-Layer Design of Elements, Domains, and Products
(2) Data Architecture Explained: 5 Archetypes and the Capability Map Behind Them